
How I Cut Our Snowflake Bill by 40% Without Touching a Single Pipeline
A battle-tested, SQL-heavy playbook from the trenches of a $300K/month data warehouse problem.
By Rafael Dias · Senior Data Engineer · May 2026 · ~2,400 words
The $87,000 Wake-Up Call
I still remember the exact moment. It was a Tuesday morning in late July when our finance VP forwarded me our cloud spend report with a single line in the email body: “Can you explain this?” Our Snowflake bill had jumped to $312,000 for the month — up from $225,000 in June. That’s an $87,000 delta in thirty days, and nobody on my team had any idea why.
Let me be clear: I love Snowflake. The separation of compute and storage, the zero-copy cloning, the near-instant elasticity — it’s genuinely one of the best platforms I’ve worked with in 12 years of data engineering. But the flip side of that power is that it’s dangerously easy to burn money. The defaults are generous, the auto-scaling is aggressive, and if you’re not watching, you will get surprised.
We had about 40 warehouses, 15 active engineering teams, and a data platform that had grown organically over three years. Nobody had ever done a systematic Snowflake cost optimization pass. That was about to change.
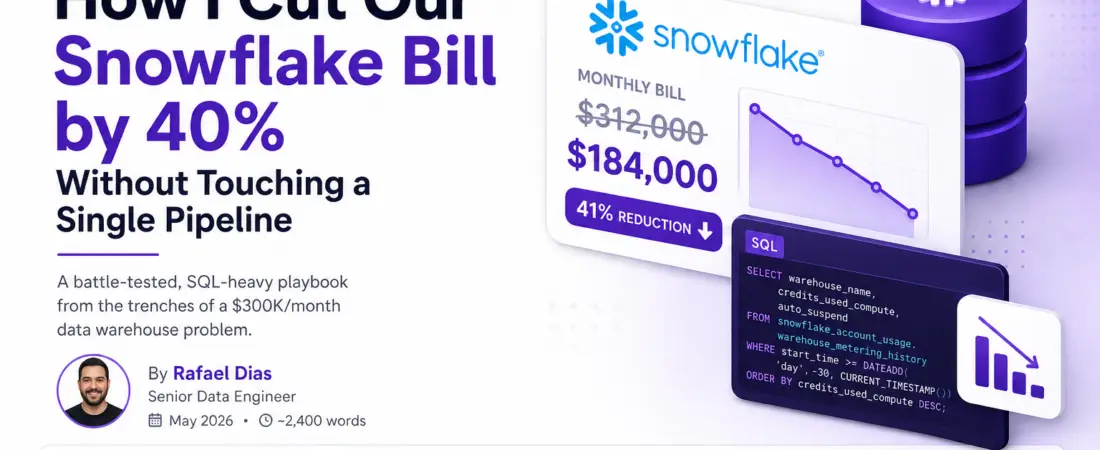
After eight weeks of analysis and incremental changes, we landed at $184,000/month — a 41% reduction. Here’s exactly how we did it, with the SQL to prove it.
1. Taming the Compute Monster
The Problem: Warehouses That Never Sleep
Compute costs — Snowflake credits consumed by virtual warehouses — made up roughly 68% of our total bill. That’s typical. What was not typical was finding 11 warehouses with AUTO_SUSPEND set to 3,600 seconds (one hour) or completely disabled. I found a PROD_REPORTING warehouse that had been running 24/7 for 19 days straight, doing absolutely nothing for 16 of those hours each day.
The first query I ran was a wake-up call on its own:
sql
-- Find warehouses with long or disabled auto-suspend
SELECT
warehouse_name,
auto_suspend,
auto_resume,
size,
ROUND(credits_used_compute, 2) AS credits_compute,
ROUND(credits_used_cloud_services, 2) AS credits_cloud
FROM snowflake.account_usage.warehouse_metering_history
WHERE start_time >= DATEADD('day', -30, CURRENT_TIMESTAMP())
GROUP BY 1,2,3,4
ORDER BY credits_compute DESC
LIMIT 20;Then I cross-referenced that against actual query activity to find the idle windows:
sql
-- Identify warehouse idle time windows (no queries running)
SELECT
warehouse_name,
DATE_TRUNC('hour', start_time) AS hour_bucket,
COUNT(query_id) AS query_count,
SUM(credits_used_compute) AS credits_burned
FROM snowflake.account_usage.query_history qh
JOIN snowflake.account_usage.warehouse_metering_history wmh
USING (warehouse_name)
WHERE qh.start_time >= DATEADD('day', -7, CURRENT_TIMESTAMP())
GROUP BY 1, 2
HAVING query_count = 0
ORDER BY credits_burned DESC;The fix was surgical but impactful. I dropped AUTO_SUSPEND to 60 seconds for dev and reporting warehouses, and 120 seconds for production ETL. For warehouses that ran scheduled jobs, I set precise schedules using Snowflake Tasks so they only warmed up when actually needed. Here’s what the remediation looked like:
sql
-- Tighten auto-suspend across reporting warehouses
ALTER WAREHOUSE prod_reporting_wh
SET auto_suspend = 60
auto_resume = TRUE
min_cluster_count = 1
max_cluster_count = 2; -- was set to 4
-- Downsize an over-provisioned dev warehouse
ALTER WAREHOUSE dev_analytics_wh
SET warehouse_size = 'SMALL'; -- was LARGE, barely usedWe also found three XL warehouses running Tableau extracts that could have run on a Medium. Engineers had sized them up during a performance incident six months ago and never rolled back. Classic.
Result: Compute optimization alone dropped our monthly credit spend by about 22%. That’s the single biggest lever in any Snowflake cost optimization project — fix your warehouses first, everything else is secondary.
2. Storage: The Silent Budget Killer
The Problem: Time Travel and Clone Sprawl
Storage feels cheap in Snowflake — until it doesn’t. We were paying for about 340 TB of effective storage when our actual data footprint was maybe 80 TB. The gap? Time Travel retention set to 90 days across almost every table (the default is 1 day, but a well-meaning engineer had bumped it enterprise-wide), plus a graveyard of zero-copy clones that nobody had cleaned up.
I queried the TABLE_STORAGE_METRICS view to get the real picture:
sql
-- Find tables with bloated time travel storage
SELECT
table_catalog,
table_schema,
table_name,
ROUND(active_bytes / POW(1024,3), 2) AS active_gb,
ROUND(time_travel_bytes / POW(1024,3), 2) AS time_travel_gb,
ROUND(failsafe_bytes / POW(1024,3), 2) AS failsafe_gb,
data_retention_time_in_days
FROM snowflake.account_usage.table_storage_metrics
WHERE time_travel_bytes > 1073741824 -- > 1 GB
ORDER BY time_travel_gb DESC
LIMIT 30;Quick context: Time Travel lets you query historical versions of your data. It’s powerful, but every day of retention you keep means Snowflake stores all the deltas. At 90 days on a high-churn table, you can easily end up with 10x the storage of the actual live data.
For most of our tables, 7 days of Time Travel was more than sufficient. Only a handful of regulated datasets genuinely needed 30+ days. We rolled out a tiered retention policy:
sql
-- Set 7-day retention for non-critical tables
ALTER TABLE analytics.events.page_views
SET data_retention_time_in_days = 7;
-- For staging/temp tables: 1 day is fine
ALTER SCHEMA raw.staging
SET data_retention_time_in_days = 1;
-- Identify and drop orphaned clones older than 14 days
SELECT
table_catalog,
table_name,
created,
DATEDIFF('day', created, CURRENT_DATE()) AS age_days,
ROUND((active_bytes + time_travel_bytes) / POW(1024,3), 2) AS total_gb
FROM snowflake.account_usage.table_storage_metrics
WHERE is_transient = 'NO'
AND clone_group_id IS NOT NULL
AND DATEDIFF('day', created, CURRENT_DATE()) > 14
ORDER BY total_gb DESC;We found 47 clones that had been created for ad-hoc analysis, debugging, or sprint reviews and were just sitting there. We built a lightweight governance process: any clone in a non-production environment auto-drops after 7 days unless explicitly tagged RETAIN=TRUE.
Result: Storage costs fell from ~$38K/month to ~$11K/month. Reducing Snowflake bills through storage tuning is often overlooked, but the math here was hard to argue with.
3. Governance: Who’s Actually Running This Thing?
The Problem: Ungoverned Access and Zombie Queries
Here’s an uncomfortable truth: in a lot of orgs, Snowflake access is handed out liberally and then never audited. We had 340 active users. When I queried actual activity over 90 days, 112 of them hadn’t run a single query. We were paying for their session overhead and, more importantly, several of them had RBAC roles that granted access to massive production warehouses.
I also found a pattern I call “tourist queries” — analysts who’d log in, accidentally kick off a full table scan on a production XL warehouse, and log out. No guardrails, no resource monitors.
sql
-- Find users with no query activity in 60+ days
SELECT
u.name AS user_name,
u.login_name,
u.last_success_login,
DATEDIFF('day', u.last_success_login, CURRENT_DATE()) AS days_since_login,
COUNT(q.query_id) AS queries_90d
FROM snowflake.account_usage.users u
LEFT JOIN snowflake.account_usage.query_history q
ON q.user_name = u.name
AND q.start_time >= DATEADD('day', -90, CURRENT_TIMESTAMP())
GROUP BY 1,2,3,4
HAVING queries_90d = 0
ORDER BY days_since_login DESC;The governance fix had two parts. First, we deactivated stale users and tightened role assignments so analysts defaulted to a dedicated ANALYTICS_WH (Medium, auto-suspend 60s) rather than production warehouses. Second — and this was the real game-changer — we deployed Resource Monitors on every warehouse over Small size:
sql
-- Create a resource monitor with hard credit cap
CREATE OR REPLACE RESOURCE MONITOR rm_analytics_monthly
WITH credit_quota = 500
frequency = monthly
start_timestamp = immediately
triggers
ON 75 percent DO NOTIFY
ON 90 percent DO NOTIFY
ON 100 percent DO SUSPEND;
ALTER WAREHOUSE analytics_wh
SET resource_monitor = rm_analytics_monthly;We also set a per-query timeout on the analytics warehouse. Nothing ruins your day like a runaway Cartesian join eating 50 credits before anyone notices:
sql
-- Cap individual query runtime to 10 minutes on analytics WH
ALTER WAREHOUSE analytics_wh
SET statement_timeout_in_seconds = 600;
-- Separate timeout for long-running ETL warehouse
ALTER WAREHOUSE etl_prod_wh
SET statement_timeout_in_seconds = 7200; -- 2 hours maxResult: Governance changes prevented runaway spend and reduced “accidental” compute by roughly 8% monthly. More importantly, we now get Slack alerts before we’re in trouble, not after. Snowflake FinOps best practices aren’t just about SQL — they’re about process.
4. Query Optimization: Stop Scanning Everything
The Problem: Full Table Scans Disguised as Business Intelligence
Even with well-sized, properly auto-suspending warehouses, you can still burn credits fast if your queries are inefficient. Snowflake charges by the second, per credit, and a query that scans a billion rows instead of a hundred million is 10x the cost. I used QUERY_HISTORY to build a “most expensive queries” leaderboard:
sql
-- Top 20 queries by credit consumption (last 30 days)
SELECT
query_id,
query_text,
user_name,
warehouse_name,
warehouse_size,
ROUND(total_elapsed_time / 1000, 1) AS elapsed_seconds,
bytes_scanned,
ROUND(bytes_scanned / POW(1024,3), 2) AS gb_scanned,
partitions_scanned,
partitions_total,
ROUND(partitions_scanned / NULLIF(partitions_total,0) * 100, 1) AS pct_partitions_scanned
FROM snowflake.account_usage.query_history
WHERE start_time >= DATEADD('day', -30, CURRENT_TIMESTAMP())
AND execution_status = 'SUCCESS'
AND warehouse_name IS NOT NULL
ORDER BY bytes_scanned DESC
LIMIT 20;The pct_partitions_scanned column is your canary in the coal mine. A well-structured query against a properly clustered table should scan maybe 5-20% of partitions. We had queries hitting 98%. Those are full scans on tables with hundreds of millions of rows, running multiple times a day.
The root causes were almost always the same: filtering on non-clustered columns, missing date predicates, or SELECT * on wide tables that then got filtered in the BI layer. Here’s what the remediation looked like for our worst offender — a daily sales aggregation that ran on an XL warehouse and took 18 minutes:
sql
-- BEFORE: full scan, no clustering key leveraged
SELECT *
FROM analytics.sales.transactions
WHERE region = 'US-WEST'
AND status = 'COMPLETED';
-- AFTER: use date filter first (clustering key), select only needed cols
SELECT
transaction_id,
customer_id,
amount_usd,
transaction_date,
region,
status
FROM analytics.sales.transactions
WHERE transaction_date >= DATEADD('day', -90, CURRENT_DATE())
AND region = 'US-WEST'
AND status = 'COMPLETED';
-- Cluster the table on the most common filter column
ALTER TABLE analytics.sales.transactions
CLUSTER BY (transaction_date, region);That query went from 18 minutes on an XL to 4 minutes on a Large. Same result, 70% less compute. We also identified several dashboards that ran the same heavy query every time a user opened a tab. We wrapped those in Snowflake’s result cache by ensuring the queries were deterministic and the warehouse settings honored the cache:
sql
-- Make sure result caching is enabled (it is by default, but verify)
ALTER SESSION SET use_cached_result = TRUE;
-- Identify queries with zero cache benefit (executed 10+ times)
SELECT
query_text,
COUNT(*) AS executions,
AVG(total_elapsed_time) / 1000 AS avg_seconds,
SUM(bytes_scanned) / POW(1024,3) AS total_gb_scanned
FROM snowflake.account_usage.query_history
WHERE start_time >= DATEADD('day', -7, CURRENT_TIMESTAMP())
AND execution_status = 'SUCCESS'
AND LEFT(query_text, 100) != ''
GROUP BY 1
HAVING COUNT(*) > 10
ORDER BY total_gb_scanned DESC
LIMIT 25;Result: Query optimization shaved another 11% off our monthly bill, and dramatically improved end-user performance as a side effect. Engineers noticed — dashboards that took 45 seconds were suddenly loading in 8.
The Final Numbers: FinOps Takeaways
Here’s where we landed after eight weeks of focused Snowflake cost optimization work:
| July baseline | $312,000/month |
| Post-optimization | $184,000/month |
| Total reduction | 41% |
| Annualized savings | ~$1.5M |
Breakdown by lever:
- Warehouse right-sizing & auto-suspend: ~22% reduction
- Storage cleanup (Time Travel + clones): ~8% reduction
- Governance & resource monitors: ~8% reduction
- Query optimization & clustering: ~11% reduction
If I had to give you three FinOps principles to walk away with, they’d be these:
1. Audit before you optimize. The queries I shared above are your starting point. You can’t fix what you can’t see. Build a weekly Snowflake spend review into your team’s rhythm — the ACCOUNT_USAGE schema is your best friend, and it’s free to query.
2. Compute is where the money is, but storage is where the surprises are. Most engineers focus on query speed and miss the Time Travel and clone bloat accumulating quietly in the background. Set a storage policy before you need one.
3. Governance is engineering work. Resource monitors, statement timeouts, and role-based warehouse assignment aren’t boring admin tasks — they’re the guardrails that prevent one bad query from blowing your entire monthly budget. Treat them like production infrastructure.
Snowflake is an incredible platform. But “incredible platform” and “unchecked spend” are not mutually exclusive. With a deliberate Snowflake FinOps practice, you can have both the performance and the predictable bill. Go run those queries. I promise you’ll find something surprising.
Rafael Dias is a Senior Data Engineer with 12 years of experience building large-scale data platforms. He writes about Snowflake, dbt, and cloud data architecture at SpiritCode.blog.