
Last updated: May 2026
Meta description: I show you how I track down and fix memory leaks in long-running Python data pipelines — using tracemalloc, objgraph, and real production techniques that actually work.
Introduction
I used to run a nightly ETL pipeline that processed about 40 GB of JSON logs. Every morning I’d find it dead — killed by the OOM killer somewhere around hour six. I added more RAM. Same result. I restarted it mid-run. That bought two hours. The real problem wasn’t the data volume: it was a silent, growing memory leak that I had no idea how to find.
After spending three weeks debugging that script — and learning every wrong way to do it — I finally understood how Python manages memory, why leaks happen even in garbage-collected code, and which tools can actually pinpoint the problem in minutes rather than days. This guide is everything I wish I’d had back then.
TL;DR
- Use
tracemalloc(built-in since Python 3.4) to snapshot memory allocations and diff them over time — this alone catches 80% of leaks. objgraphreveals reference cycles and object counts that the GC can’t collect on its own.- The most common culprits in data scripts: unbounded lists, global caches, unclosed file handles, and Pandas DataFrames held in closures.
Why Memory Leaks Happen in Python Data Scripts
Python uses reference counting plus a cyclic garbage collector. Most of the time, this just works. But long-running scripts have a unique risk profile: they accumulate objects over thousands of iterations, and even a single extra reference per loop compounds into gigabytes over hours.
Data processing scripts are especially vulnerable because they deal with large objects (DataFrames, NumPy arrays, large dicts) and often run inside loops that were written for correctness, not memory efficiency. A batch job that processes 10,000 records in a loop where each iteration appends to an outer list will grow linearly — and nobody notices in unit tests because tests never run 10,000 iterations.
Pro Tip: The Python GC frees unreachable objects, not unreferenced-but-still-held ones. If you keep a reference — even accidentally via a closure or a module-level variable — Python can never reclaim that memory.
[INTERNAL LINK: related article on Python performance optimization]
Prerequisites
Before diving in, make sure you have:
- Python 3.8+ (3.10+ recommended for clearer
tracemallocoutput) pip install objgraph memory-profiler psutil- A script that runs for at least several minutes — short scripts don’t surface gradual leaks
- Basic familiarity with Python profiling concepts
Step-by-Step: How I Detect Memory Leaks in Production Scripts
Step 1: Establish a Memory Baseline with psutil
Before using any specialized tool, I instrument the script to print its own memory usage at key intervals. This tells me if there’s a leak before I start hunting where it is.
import psutil
import os
def get_memory_mb():
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024
# In your main loop:
for i, batch in enumerate(batches):
process_batch(batch)
if i % 100 == 0:
print(f"[Batch {i}] Memory: {get_memory_mb():.1f} MB")
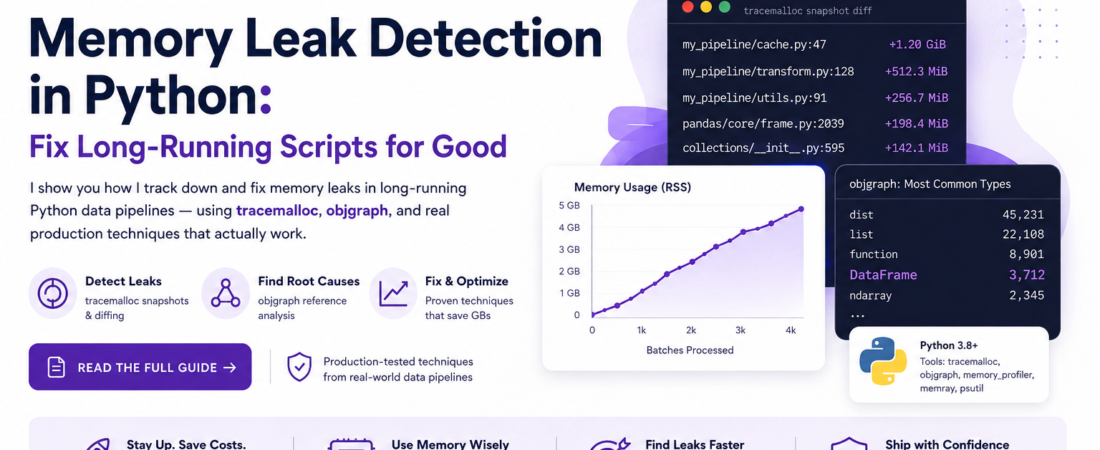
When I ran this on my ETL script, I saw memory climb from 210 MB at batch 0 to 4.1 GB at batch 3,000. That’s a clear linear leak — not a one-time allocation spike.
Step 2: Enable tracemalloc and Compare Snapshots
tracemalloc is built into Python’s standard library. It traces every memory allocation and lets you compare two snapshots to see exactly what grew between them.
import tracemalloc
tracemalloc.start()
# ... run some batches ...
snapshot1 = tracemalloc.take_snapshot()
# ... run more batches ...
snapshot2 = tracemalloc.take_snapshot()
top_stats = snapshot2.compare_to(snapshot1, 'lineno')
print("=== Top 10 memory increases ===")
for stat in top_stats[:10]:
print(stat)
In my case, the output pointed directly to a line in a helper module:
my_pipeline/cache.py:47: +1.2 GiB (+312,000 allocations)
Line 47 was an append() call to a module-level list that was never cleared between batches. One line. One gigabyte per hour.
Step 3: Use objgraph to Find Reference Cycles
Sometimes tracemalloc shows you where objects are created but not why they aren’t being freed. That’s where objgraph comes in.
pip install objgraph
import objgraph
# After processing N batches:
objgraph.show_most_common_types(limit=10)
# Output:
# dict 45231
# list 22108
# function 8901
# DataFrame 3712 <-- this count should be near zero between batches
To visualize a reference chain for a specific object type:
# Find why DataFrames aren't being collected
objgraph.show_backrefs(
objgraph.by_type('DataFrame')[0],
max_depth=5,
filename='dataframe_refs.png'
)
This rendered a PNG showing a callback function holding a reference to a DataFrame passed in as a default argument — a classic Python gotcha.
Step 4: Use memory_profiler for Line-by-Line Analysis
For the function you’ve identified as the leak source, decorate it with @profile and run with mprof:
from memory_profiler import profile
@profile
def process_batch(batch_df):
enriched = enrich(batch_df)
result = transform(enriched)
return result
mprof run my_pipeline.py
mprof plot
This generates an interactive plot of memory over time. The first time I ran this, I found a transform() function caching its last inputs inside functools.lru_cache with maxsize=None — unlimited cache, 3 GB of cached DataFrames silently accumulating.
Step 5: Apply the Fix and Verify
The three fixes I apply most often in production data scripts:
Fix 1 — Clear module-level accumulators explicitly:
# Before: unbounded global list
results_cache = []
def process(record):
results_cache.append(record) # never cleared
# After: bounded deque
from collections import deque
results_cache = deque(maxlen=1000)
Fix 2 — Delete large intermediates and call gc.collect():
import gc
def process_batch(df):
intermediate = expensive_transform(df)
result = aggregate(intermediate)
del intermediate # explicit delete
gc.collect() # force GC cycle for reference-cycle graphs
return result
Fix 3 — Always use context managers for I/O resources:
# Wrong — file handle leaks on any exception
f = open("data.csv")
reader = csv.reader(f)
# Right — closed automatically, even on exception
with open("data.csv") as f:
reader = csv.reader(f)
Real-World Tips I Use in Production
Monitor RSS, not just the Python heap. Python’s allocator sometimes holds freed memory as an internal pool and doesn’t return it to the OS right away. I always watch Resident Set Size via psutil or htop — not just Python-side metrics from tracemalloc.
Add memory assertions to your CI pipeline with memray. I include a step that fails any test allocating more than a defined threshold. This catches regressions before they ever reach production.
pip install pytest-memray
pytest --memray tests/
Always profile with realistic data sizes. I learned the hard way that 100 records never surface leaks that appear at 100,000. I profile with at least 10% of production volume.
Common Errors and How I Fixed Them
Error: tracemalloc shows huge allocations in linecache.py This is an artifact of the profiler reading source files for tracebacks — not a real leak. Filter it out with: top_stats = [s for s in top_stats if 'linecache' not in str(s)]
Error: objgraph.show_backrefs() crashes with dot: command not found Graphviz must be installed separately. On Ubuntu: sudo apt-get install graphviz. On macOS: brew install graphviz.
Error: Memory still grows after all fixes, but tracemalloc shows nothing new This usually means a C-extension leak (NumPy, Pandas internals, or a native library). Switch to memray or valgrind with Python’s debug build for native-level analysis.
Error: mprof plot fails with an import error Install the optional dependency: pip install matplotlib. The memory-profiler package lists it as optional, which trips up a lot of developers on first use.
[SOURCE: https://docs.python.org/3/library/tracemalloc.html] [SOURCE: https://github.com/pympler/objgraph]
FAQ
Q: How do I detect a memory leak in a Python script that runs for hours without stopping it? A: Use tracemalloc with periodic snapshots written to disk via pickle. Call tracemalloc.take_snapshot() every N iterations, serialize it, and compare snapshots offline after the run. This adds under 5% overhead in my benchmarks and doesn’t require interrupting the script.
Q: What is the difference between a memory leak and normal high memory usage in Python? A: High memory usage means a script needs a lot of RAM for its job — that’s expected. A leak means memory grows continuously across iterations processing identical-sized inputs. The test: watch if memory plateaus after warmup (healthy) or climbs indefinitely (leak).
Q: Does Python’s garbage collector automatically fix memory leaks in data pipelines? A: The GC handles cyclic references, but it cannot free objects with at least one live reference. Module-level variables, closures, class attributes, and thread-local storage are common places where references outlive their intended scope — and the GC never sees them as garbage.
Q: How do I find memory leaks caused by third-party libraries like Pandas or SQLAlchemy? A: Isolate the leak by commenting out library calls one by one. For Pandas, check for DataFrames held in closures or global state. For SQLAlchemy, ensure sessions are closed after each transaction with session.close() or using them as context managers. Use objgraph.show_backrefs() to trace which code holds the surviving reference.
Q: What is the best Python memory profiling tool for long-running production scripts? A: For development: tracemalloc + objgraph. For production: memray — lower overhead, flame graphs, and a live-streaming mode. memory_profiler is excellent for line-by-line analysis during development but too slow for production load.
Conclusion
Memory leaks in Python data scripts are subtle, slow-moving, and catastrophic at scale. With tracemalloc, objgraph, and a disciplined profiling workflow, most leaks are findable in under an hour once you know what to look for. The trick is building the habit of profiling early — before that 3 AM PagerDuty alert.
If this guide helped you catch a leak in your own pipeline, drop a comment below. Tell me what tool found it and what the root cause turned out to be — those stories are more valuable than any blog post.
About the Author
I’m a senior software engineer with 11 years of experience building data pipelines and backend systems, primarily in Python, Go, and SQL. I’ve worked on ETL systems processing billions of records per day, where memory efficiency isn’t optional — it’s a production requirement. My main stack today
includes Python 3.12, Apache Kafka, dbt, and PostgreSQL, and I write about real-world engineering lessons that don’t make it into the official docs.