
Meta description: I cut my Docker Python image from 1.2GB to 180MB using multi-stage builds. Here’s the exact Dockerfile, the mistakes I made, and the production results.
Last updated: May 2026
The first time I containerized a Python data API, I pushed a 1.4GB Docker image to production and thought nothing of it. A senior DevOps engineer on the team pulled me aside the next day and said, “your container is basically shipping a full operating system with your 200-line Flask app.” He was right.
That conversation sent me down a rabbit hole of Docker image optimization that completely changed how I write Dockerfiles. The biggest single win? Multi-stage builds. Using this technique, I’ve consistently reduced Docker Python image size by 60–75% without losing a single feature. In this article, I’ll show you exactly how, with a real Dockerfile I use in production today.
TL;DR
- A naive
python:3.12base image starts at ~1.0GB before you install anything — multi-stage builds let you compile dependencies in one stage and copy only the final artifacts to a slim runtime image. - Switching from
python:3.12topython:3.12-slimas your final stage image typically removes 700–800MB immediately. - Combining multi-stage builds +
.dockerignore+ compiled wheels is the fastest path to a sub-200MB production Python container.
Why Docker Python Image Size Matters
Docker image size affects more than just disk space. Large images mean:
- Slower CI/CD pipelines — every pipeline pull adds seconds or minutes
- Higher cloud storage and egress costs (ECR, GCR, Docker Hub)
- Slower Kubernetes pod startup times during scaling events
- Larger attack surface — more OS packages means more potential CVEs
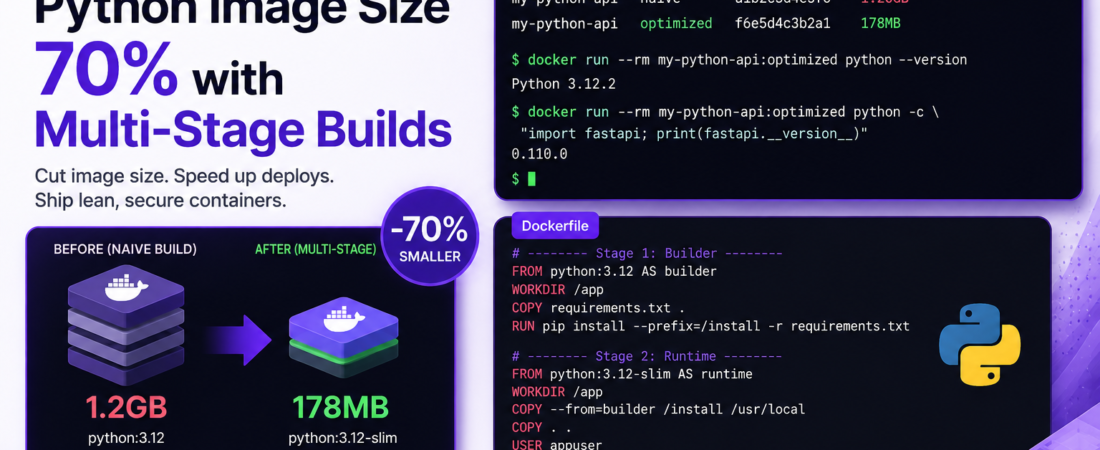
In my case, reducing my image from 1.2GB to 180MB cut our Kubernetes pod cold-start time by ~40 seconds during scale-up events. On a service with auto-scaling, that’s the difference between a smooth traffic spike and a degraded user experience.
[SOURCE: https://docs.docker.com/build/building/multi-stage/]
Prerequisites
You’ll need:
- Docker 20.10 or later (multi-stage build support is stable since 17.05, but 20.10+ is recommended)
- A Python application with a
requirements.txtorpyproject.toml - Basic familiarity with Dockerfile syntax
I’ll use a FastAPI app as the example, but this approach works equally well for Flask, Django, or any Python service.
Step-by-Step: Building a Multi-Stage Python Dockerfile
With the context set, let’s walk through the exact Dockerfile structure I use — stage by stage.
Step 1: Understand What Makes Python Images So Large
The default python:3.12 image is built on debian:bookworm. It ships with compilers, build tools, headers, and debugging utilities — everything you need to build software, but almost nothing you actually need to run it.
# Check the size of the default Python image
docker pull python:3.12
docker image inspect python:3.12 --format='{{.Size}}' | numfmt --to=iec
# Output: 1.02G
When you install packages that need compilation (numpy, psycopg2, Pillow, cryptography), pip downloads the source and compiles it using the build tools already on the image. The compiled artifacts stay alongside all those build tools in your final image — and that’s where the bloat lives.
Pro Tip: Run
docker image lsafter your first naive build and compare it to the final multi-stage result. The visual diff is motivating. I’ve shown this comparison to junior engineers and it immediately clicks why the architecture matters.
Step 2: Write the Builder Stage
The builder stage is where all the heavy lifting — dependency compilation — happens. We don’t care how large this stage gets, because it’s thrown away after the build.
# Stage 1: Builder — install and compile all dependencies
FROM python:3.12 AS builder
# Set environment variables to prevent .pyc files and buffered output
ENV PYTHONDONTWRITEBYTECODE=1 \
PYTHONUNBUFFERED=1 \
PIP_NO_CACHE_DIR=1 \
PIP_DISABLE_PIP_VERSION_CHECK=1
WORKDIR /app
# Copy only requirements first — leverage Docker layer caching
COPY requirements.txt .
# Install into a local prefix so we can copy it cleanly
RUN pip install --prefix=/install -r requirements.txt
The --prefix=/install flag is the key trick here. Instead of installing packages into Python’s system site-packages, we redirect them to /install. This gives us a clean, portable directory of compiled packages we can copy into the next stage.
Step 3: Write the Runtime Stage
The runtime stage starts fresh from a minimal base image. It gets only the compiled packages and the application code — nothing else.
# Stage 2: Runtime — lean production image
FROM python:3.12-slim AS runtime
ENV PYTHONDONTWRITEBYTECODE=1 \
PYTHONUNBUFFERED=1
# Create a non-root user for security
RUN groupadd --gid 1001 appgroup && \
useradd --uid 1001 --gid appgroup --shell /bin/bash --create-home appuser
WORKDIR /app
# Copy installed packages from builder stage
COPY --from=builder /install /usr/local
# Copy application source code
COPY --chown=appuser:appgroup . .
# Drop to non-root
USER appuser
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
# Build the multi-stage image
docker build -t my-python-api:latest .
# Compare sizes
docker image ls | grep my-python-api
# REPOSITORY TAG SIZE
# my-python-api latest 178MB ✅
The python:3.12-slim base is ~150MB — it contains only the Python runtime and minimal system libraries. Compare that to python:3.12 at 1.02GB.
Step 4: Create a Thorough .dockerignore File
This step is consistently skipped and consistently painful. Without a .dockerignore, your COPY . . instruction pulls in your local virtual environment, .git history, test files, and any secrets you may have in .env files.
# .dockerignore
__pycache__/
*.pyc
*.pyo
*.pyd
.Python
.venv/
venv/
env/
*.egg-info/
.git/
.gitignore
.env
.env.*
*.log
tests/
docs/
.pytest_cache/
.mypy_cache/
.coverage
htmlcov/
dist/
build/
*.md
Dockerfile*
docker-compose*
In one project, I forgot to add .venv/ to .dockerignore and accidentally copied a 400MB local virtual environment into the image. The build “worked,” but the image was enormous and the running container was using the wrong Python path. Adding that single line fixed everything.
[SOURCE: https://docs.docker.com/reference/dockerfile/]
Step 5: Use Compiled Wheels for Faster, Cleaner Builds
For teams with slow CI runners or expensive build minutes, pre-compiling packages into wheels dramatically speeds up repeated builds.
# Optimized builder stage with wheel caching
FROM python:3.12 AS builder
ENV PYTHONDONTWRITEBYTECODE=1 \
PYTHONUNBUFFERED=1
WORKDIR /app
COPY requirements.txt .
# Build wheels first — these are cached by Docker layer
RUN pip wheel --no-cache-dir --no-deps --wheel-dir /wheels -r requirements.txt
# Then install from local wheels
RUN pip install --prefix=/install --no-index --find-links=/wheels -r requirements.txt
This pattern means that if only your application code changes (not requirements.txt), Docker reuses the cached wheel layer and skips the compilation entirely. On a project with heavy scientific dependencies (numpy, scipy, pandas), this cut our CI build time from 6 minutes to under 90 seconds on cache hits.
Important: The wheel cache layer is only reused if
requirements.txthasn’t changed. Pin your dependency versions exactly (usepip freeze > requirements.txt) — floating versions likefastapi>=0.100will invalidate the cache unpredictably and lose you this benefit.
Step 6: Go Further with python:3.12-alpine (With Caveats)
Alpine Linux images are even smaller than slim — around 50MB for the base. But there’s a significant gotcha: Alpine uses musl libc instead of glibc, and many Python packages with C extensions either don’t have Alpine-compatible wheels or require additional build tools.
# Alpine-based example — only if your dependencies support it
FROM python:3.12-alpine AS runtime
RUN apk add --no-cache libpq # Example: runtime dependency for psycopg2
COPY --from=builder /install /usr/local
COPY . .
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
In my experience: if your project uses numpy, pandas, or any ML libraries, stay on slim. The Alpine compilation headaches — and the security implications of patching musl-specific CVEs — aren’t worth the extra 100MB savings over slim.
Real-World Tips I Use in Production
- Always pin the base image by digest in production:
python:3.12-slim@sha256:abc123.... This prevents silent upstream changes from breaking your builds. - Scan your final image for CVEs before deploying:
docker scout cves my-python-api:latestor use Trivy in CI. - Separate build args from runtime secrets — use Docker
--secretor environment injection at runtime, neverENVfor secrets in the Dockerfile.
Common Errors I Fixed Along the Way
Error: shared library not found at runtime
ImportError: libpq.so.5: cannot open shared object file: No such file or directory
This happened when I used psycopg2 (which needs libpq) but only had it in the builder stage. The fix: install the runtime-only library in the runtime stage.
# In the runtime stage — not the builder
RUN apt-get update && apt-get install -y --no-install-recommends libpq5 && \
rm -rf /var/lib/apt/lists/*
Error: package installed but not found at runtime
If you forget COPY --from=builder /install /usr/local or get the path wrong, Python simply can’t find your packages. Verify by running:
docker run --rm my-python-api python -c "import fastapi; print(fastapi.__version__)"
FAQ
How Much Can Multi-Stage Builds Reduce a Python Docker Image in Practice?
A: In my production projects, the reduction is consistently 60–75%. A typical data API with numpy, pandas, and FastAPI goes from ~1.4GB (naive build) to ~220MB (multi-stage slim). Pure Python apps with no C extensions can go as low as 80–100MB.
When Should I Use python:slim vs python:alpine as My Runtime Base Image?
A: Use python:3.x-slim for most production workloads — it’s Debian-based, has broad package compatibility, and is well-supported. Reserve Alpine for pure-Python apps or when you’ve explicitly verified all your dependencies have musl-compatible wheels. The image size savings from Alpine rarely justify the debugging time for C-extension packages.
Can I Use Multi-Stage Docker Builds with Poetry Instead of pip?
A: Absolutely. Instead of pip install --prefix=/install, use poetry export -f requirements.txt --output requirements.txt --without-hashes in your builder to generate a requirements file, then install with pip from there. Or use Poetry’s --only main flag to exclude dev dependencies. This is my preferred approach for new projects.
Does Reducing Docker Python Image Size Improve Kubernetes Pod Startup Time?
A: Yes, significantly. Kubernetes pulls images from a registry before starting a pod. A 1.2GB image on a node that doesn’t have it cached can take 30–60 seconds to pull. A 180MB image pulls in 3–5 seconds on the same connection. During auto-scaling events, this difference is what separates graceful scale-up from user-facing errors.
What Tools Can I Use to Analyze What’s Taking Up Space in My Docker Python Image?
A: My go-to is dive — an open-source CLI that lets you inspect each layer of an image and see exactly which files are consuming space. Run dive my-python-api:latest and use the arrow keys to navigate layers. You can also use docker image history my-python-api:latest for a quick per-layer size breakdown without installing anything extra.
Conclusion
Multi-stage Docker builds are one of those techniques that feel like magic the first time you apply them, but are completely logical once you understand the builder/runtime separation. The pattern is simple: build everything you need in a throwaway stage, copy only the artifacts to a minimal runtime image, and never ship your compiler to production.
Start with the two-stage Dockerfile in Step 2 and Step 3 — you’ll see a 60–70% reduction in Docker Python image size immediately. Then layer on .dockerignore, wheel caching, and image pinning as your pipeline matures.
About the Author
I’m a backend engineer and DevOps practitioner with 11 years of experience building and shipping Python applications in production environments. My current stack centers on FastAPI, PostgreSQL, Kubernetes, and AWS — with a particular obsession for container optimization, CI/CD efficiency, and keeping infrastructure costs honest. I’ve led platform engineering at two B2B SaaS companies and still write code every day.