
Scaling the Unscalable: Why “LLM-as-a-Judge” is the New Gold Standard for AI Evals
In my years building and deploying models here in the Valley, I’ve seen a recurring pattern that kills promising AI products before they even hit prod. Engineering teams spend weeks perfecting a RAG (Retrieval-Augmented Generation) pipeline, only to realize they have no objective way to tell if the output is actually good.
Early on, we all fall into the same trap: manual spot-checking. You and your lead engineer sit in a room, run ten queries, nod because the answers “look right,” and ship it.
I call this the “silent killer” of AI reliability. Manual reviews don’t scale, they’re riddled with human fatigue, and they provide zero protection against regressions when you swap out an embedding model or tweak your prompt. If you want to move fast without breaking your CX, you need automated AI testing. Specifically, you need the LLM-as-a-Judge pattern.
What exactly is LLM-as-a-Judge?
The concept is elegant in its simplicity: we use a highly capable “Teacher” model (like GPT-4o or Claude 3.5 Sonnet) to evaluate the outputs of our “Student” model (which might be a smaller, faster, or specialized LLM).
Instead of relying on outdated NLP metrics like ROUGE or BLEU—which are notoriously bad at capturing semantic nuance—we leverage the reasoning capabilities of an LLM to score responses based on specific criteria.
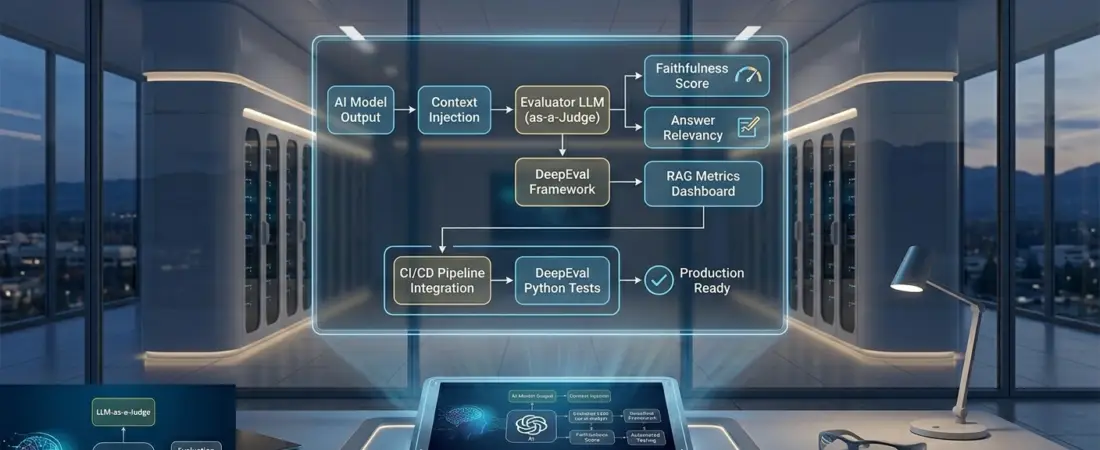
The Metrics That Matter
In my projects, I don’t just ask a judge if an answer is “good.” I break it down into quantifiable RAG evaluation metrics:
- Faithfulness: Does the answer stick to the provided context, or is it hallucinating?
- Answer Relevancy: Does the response actually address the user’s intent?
- Contextual Precision: Is the retrieved information actually the right stuff for the job?
My Go-To Toolkit: Frameworks over Scripts
I’ve learned the hard way that writing custom Python scripts to “ask GPT-4 if this is okay” is a maintenance nightmare. You need a framework that treats evals as a first-class citizen.
- DeepEval: This is currently my top recommendation for teams serious about unit testing for LLMs. It’s “Pytest for LLMs.” It integrates beautifully into CI/CD pipelines, allowing you to fail a build if your “Faithfulness” score drops below a 0.7 threshold.
- Ragas: If you are purely focused on RAG, Ragas is the industry standard for measuring the “RAG Triad” (Faithfulness, Answer Relevance, and Context Relevance).
- LangSmith: For teams already deep in the LangChain ecosystem, LangSmith provides incredible visibility and a UI-driven way to run evaluators over historical traces.
The Elephant in the Room: Bias and Reliability
I’d be doing you a disservice if I said LLM-as-a-Judge was a silver bullet. It’s not. In my experience, you have to actively mitigate Self-Correction Bias (where a model prefers its own style) and Position Bias (where the judge favors the first or last option provided).
How I mitigate these risks:
- Few-Shot Rubrics: I never give the judge a vague task. I provide a strict scoring rubric (1-5) with clear examples of what constitutes a “3” versus a “5.”
- Chain-of-Thought (CoT): I always force the judge to “think out loud” before giving a score. This significantly increases the correlation between the AI judge and a human expert.
- The “Judge the Judge” Loop: Periodically, I run a small subset of the AI’s evaluations by a human. If the delta is too high, we tune the evaluation prompt.
Final Thoughts
The era of “vibes-based” engineering is over. If you aren’t quantifying your AI reliability, you’re just guessing.
Transitioning to an LLM-as-a-Judge workflow was the single biggest turning point for my teams in terms of deployment velocity. It turns the “black box” of LLM outputs into a measurable, optimizable dashboard.
Are you still relying on manual evals, or have you started automating your judge prompts? Let’s talk about it in the comments—I’m curious to see which rubrics are working for you.